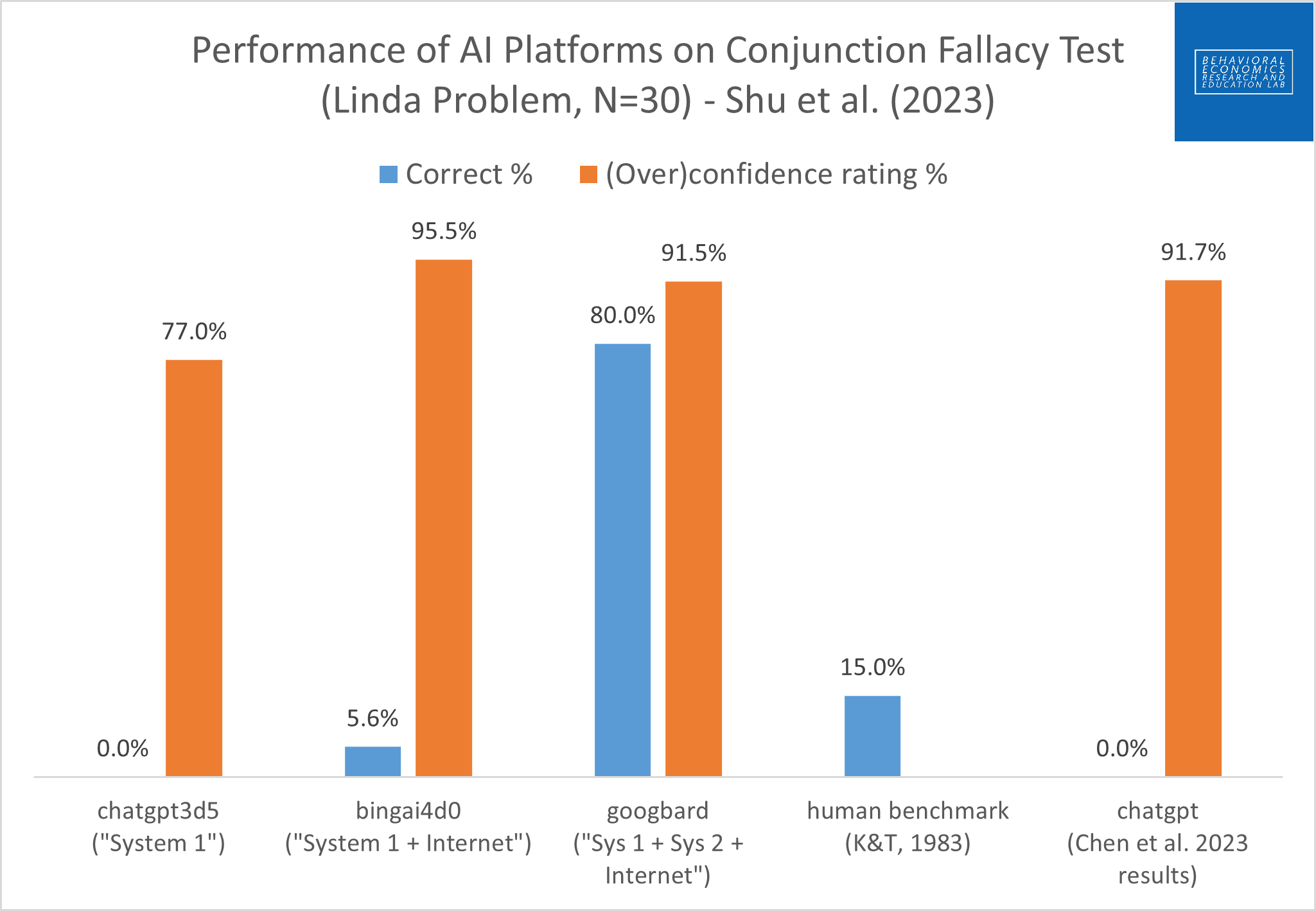
As a follow-on post to summer 2023 exploratory work that is happening with the Behavioral Economics Research and Education (BERE) Lab, we’ve started to compile early results. Here are some test result summaries of different AI platforms based on the conjunction fallacy test (Linda problem). Note that platforms vary based on degree of live access to the internet and incorporation of slower System 2 thinking influences (although these characteristics are also confounded with platform implementation). Here we test ChatGPT 3.5, Bing Chat AI (based on GPT 4), and Google Bard.
Interesting questions to reflect on:
– How do AI platforms differ?
– Which gets things right?
– Which do you trust?
– To what extent will AI adoption get impacted by use case, accuracy, and trust?